Scraping HTML Websites with Beautiful Soup
Scraping HTML websites for information is a common task. This blog post shows how to extract
information via the Beautiful Soup (bs4) Python library.
Scraping HTML websites for information is a common task. This blog post shows how to extract
information via the Beautiful Soup (bs4) Python library.

Laser cutting with plywood, acrylic glass, or paper can be fun! In this post, I'll share which laser cutter I bought last year, what I created so far, and what I learned along the way.

Installing Xubuntu 20.04 LTS on a new Lenovo Thinkpad L15 was relatively painless, but involves a few steps. Especially the pre-installed Windows 10 makes it harder than necessary.

Secure Scuttlebutt (SSB) is a Free-as-in-Freedom decentralized (p2p) social network. I joined the "Scuttleverse" last December. The Scuttleverse is a strange place. Strange, but friendly and welcoming.
TSV (Tab-Separated Values) is a simple text format for tabular data. I'll describe how I work with TSV files on the command line and why TSV is my favorite format for tabular data.

Naming is hard. Naming is communication. Going bananas with naming microservices? Probably something you will regret! This post proposes a few guidelines to follow when naming internal applications and components.

Date formats are plentiful and humans are creatures of habit. Communication in an international context mostly works, but date formats cause unnecessary confusion. Which date format to use?
How to save cloud costs when running Kubernetes? There is no silver bullet, but this blog post describes a few tools to help you manage resources and reduce cloud spending.
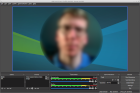
Many people are now working remote ("WFH"). How to make the best out of video calls with Google Hangouts Meet? This blog post describes how to use OBS Studio with a virtual camera device (video loopback) on Linux to add effects and scenes for Google Meet video calls.
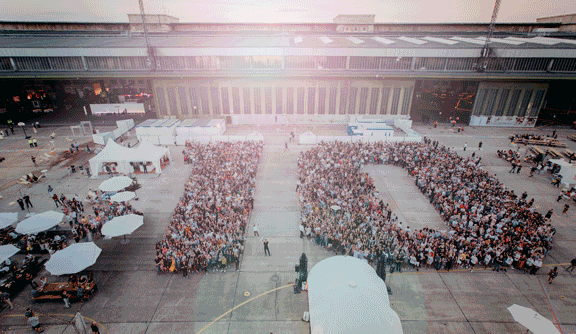
One decade. 10 years. In one company. Or did I actually work in four companies? This blog post is the long planned successor to my 2013 post My three year journey into Zalando Technology.