One Decade in Zalando Tech
Posted:
One decade. 10 years. In one company. Or did I actually work in four companies? This blog post is the long planned successor to my 2013 post My three year journey into Zalando Technology.
DISCLAIMER: Views expressed within this post are entirely my own, and may not reflect the views of my employer or their leadership.
Zalando is one of the few European unicorns: its revenue grew from 6 million euros in 2009 to ~6,500 million euros (2019). In terms of employees, we grew from ~180 in 2010 to around ~14,000 (2019). Our SVP Jan Bartels recently talked about Zalando's growth at HPI Startup Talks in January. He described four stages, from "newborn" (2009-2011) to "Gen Z" (2018+).
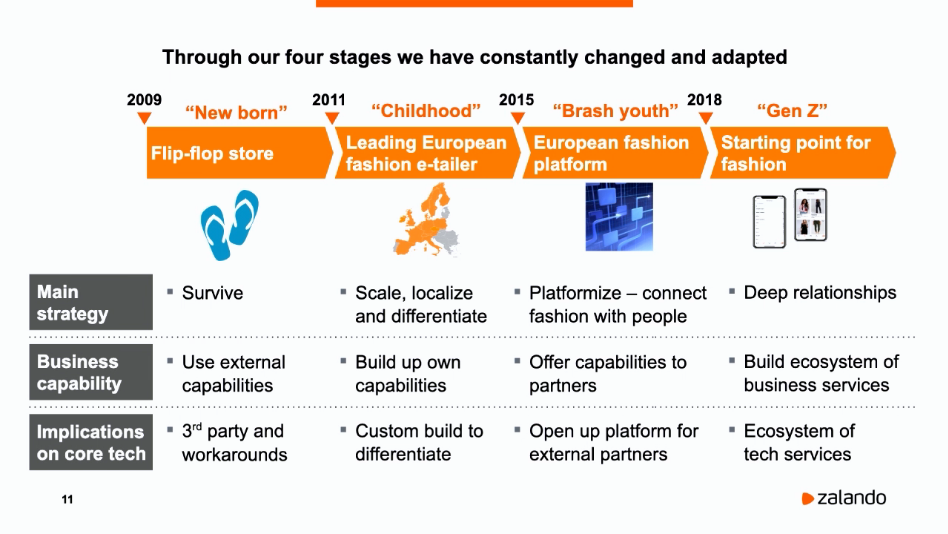
I will use slightly different phases and describe them from my own limited perspective.
"Newborn": Magento/PHP to Java/PostgreSQL
I started at Zalando on 1st of February 2010 in Berlin. It was a cold winter — the only cold Berlin winter I can remember. I joined a PHP shop. Everything was PHP/MySQL, except one team doing Java. This changed during Summer 2010: we rewrote the Magento/PHP/MySQL shop in Java/Spring/Tomcat with PostgreSQL. Our Magento/PHP/MySQL stack reached its limits, both in terms of scaling as well as adaptability. The now "legacy" monoliths were born, including "Jimmy".
"Childhood": Expansion
2011 was a year of expansion. We rolled out the Netherlands and France already at the end of 2010 — Italy, Great Britain, Austria and Switzerland followed 2011. Expansion not only meant rolling out new countries but also benefited German customers as we introduced our Partner Program with tons of additional products for our shop.
2012 was the year of "ZEOS Order" for me. We dumped our Enterprise ERP (Semiramis) and created home-grown services for order and payment processing. These used the same "Zomcat" stack as all production "ZEOS" services. We managed to show that our new setup could easily scale to handle ten to hundred times the order volume of that time (March 2012). The term ZEOS was coined in 2012. It stands for Zalando Ecommerce Operating System. Its tech stack looked like this:
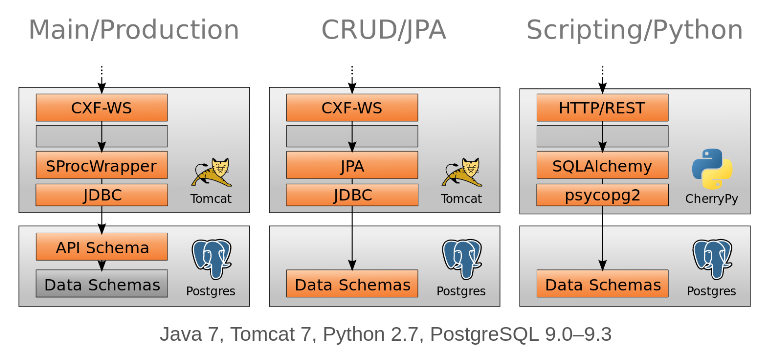
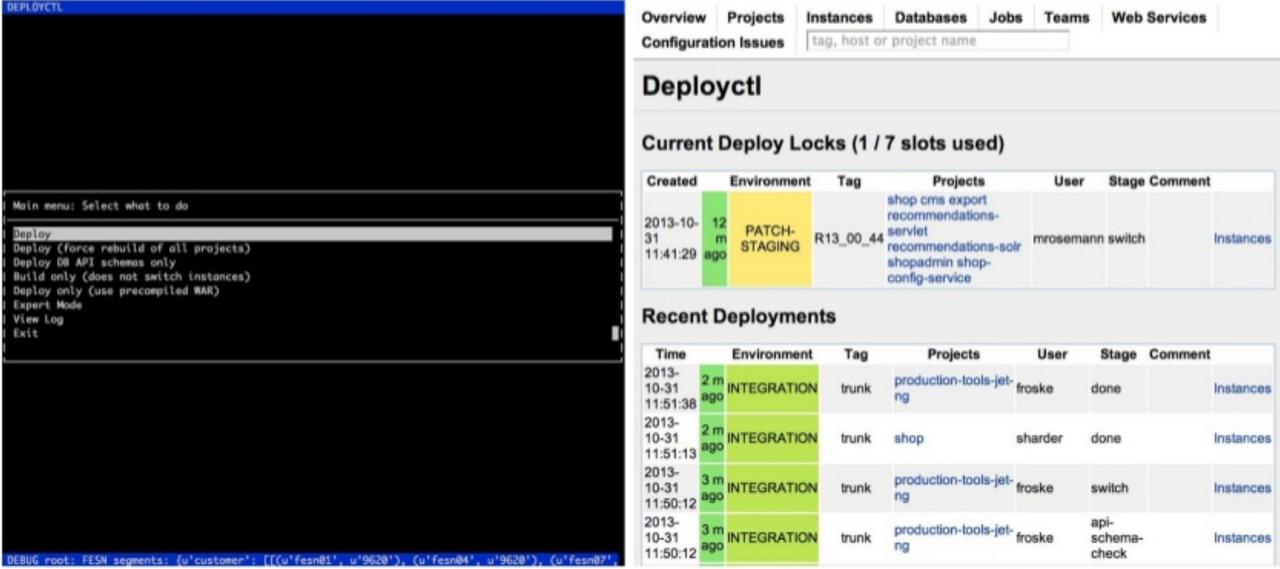
2012 was also the birth of a new "Platform" team structure. The "Platform" team provides all necessary Technology infrastructure to other feature/topic oriented teams: System Engineering, Database Engineering, Platform/Software Engineering and Security Advisory. I became Technical Lead for the Platform/Software team. My team was responsible for various developer tools, e.g. monitoring (ZMON) and deployments. The deployment tooling ("DeployCtl") looked like this:
2013 was Zalando's fifth birthday. I wrote a blog post for this occasion about my first three years in Zalando. You can find it archived on GitHub.
2014 was the year of Zalando's IPO. We kicked off a project to make our data center usage more efficient. After looking at Docker, Pivotal, and also Kubernetes (which was first announced 2014), we decided to prototype a new container management platform "Pequod". In hindsight, it was a wise decision to stop the project and concentrate on our move into the cloud. End of 2014, we started looking into how to migrate to AWS.
"Brash youth": Microservices in the Cloud
2015 was a year of radical change. Zalando Tech went into the AWS cloud, started with microservices, and pulled through a major organizational change: "Radical Agility". There are a handful of talks about this and our cloud setup "STUPS", e.g. at AWS Berlin Summit 2015 or GOTO 2016.
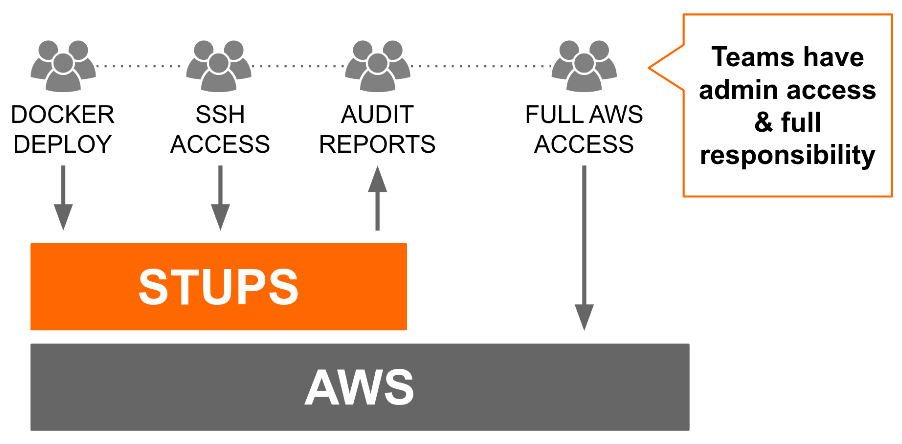
What did we get right?
First of all: we did get a lot right! The pre-2014 setup would not have brought us where we are now.
Our approach for moving into the cloud was rearchitecting the platform towards containerized microservices which talk via REST APIs and OAuth with each other. Introducing Docker, REST API guidelines, and OAuth was a good decision. Containers/APIs/OAuth are also the core of our current Kubernetes platform. Our RESTful API and Event Scheme Guidelines still serve us well and prevent every API from looking different.
We also introduced a central application registry (Kio) in 2015. This is one essential ingredient to manage a grown microservice landscape. I still meet a lot of companies who don't have any central service catalog (we call it application registry) and thus have a hard time getting an overview of their landscape.
We got rid of a strict Jira-dependency for compliant software development. Jira was previously our means to ensure that software development complies with German law (workflow with 4-eyes). However, this would break as soon as autonomous teams start using GitHub issues/PRs without Jira. We therefore redesigned our workflow to primarily rely on GitHub PRs for code reviews with 4-eyes approval ("+1" PR comments). I see this as a great decision as code reviews are good practice anyway [1]. I don't need to tell you what most developers think about Jira [2].
What would I try to do differently?
It's easy to spot mistakes in hindsight and I'm aware of hindsight bias. That being said, what would I try to do differently in 2015 with my current (2020) knowledge?
We gave autonomy to teams to freely choose their technology stack. While we only allowed Java/Tomcat/PostgreSQL and Python for our data center workloads, teams could now write microservices in whatever language they preferred. We introduced the Zalando Tech Radar to give guidance, but it turned out that changes on the Tech Radar were mostly additions — we had challenges in maintaining the tech landscape. Scala and Clojure were introduced in 2015. Elm, Go, Haskell, Kotlin, Rust, and TypeScript joined later [3]. 5 years later, I see similar (CRUD) REST services written in 6 different languages. This prevented us from providing the best library & platform support and hurts productivity at scale. [4]
Team autonomy also meant that each team can give themselves their own name and identity. This was a very bad idea. Teams mostly chose "fun" names with no relation to their team purpose/domain, e.g. "nobody" or "teapot". The cognitive overhead to have 260+ engineering teams known by their "fun" IDs is an incredible waste of brain power. Sadly this also extended to application names: teams started to have naming schemes and used them to name their services (e.g. "coastal shapes", "characters from Agatha Christie's Poirot"). I still feel bad because I think I could have influenced this in 2015. The first "new" autonomous team was the team I was part of, "stups". If only we would have set a good example of a meaningful team name/ID (e.g. "cloud-infrastructure") and introduced naming constraints! [5]
Another mistake I'm not proud of is not introducing CI/CD from the start. We introduced the AWS/STUPS infrastructure as a set of tools to allow teams to deploy to AWS with Docker in a compliant way. The main tool for teams to deploy was Senza, a command line interface to generate and update CloudFormation stacks. There was no Continuous Delivery out-of-the-box. Later we fixed this by integrating Senza with our managed Jenkins offering — but it was already too late: teams got used to deploying from their local machine.
There are a number of other things I would now approach in a different way, but I won't share them to protect the innocent ;-)
2016 was largely shaped by teams adopting the new AWS/STUPS infrastructure and migrating to microservices with Docker and OAuth.
Dedicated Ownership
2017 was another year of organizational change. Zalando Technology was so far separated from the business/commercial departments. This separation led to a number of pain points. 2017 resolved those by introducing the concept of Dedicated Ownership (single-threaded leader). Tech was now everywhere.
2017 was also a big change for myself. The organizational change introduced a new area "Developer Productivity". I felt this was the right topic to drive forward, so I took over the leadership role for five teams. The transformation from a "Tech Infrastructure" department to a customer-centric "Developer Productivity" area was a big challenge. I hired our first product manager for platform teams. There was a lot to learn and impact to have. We started listening to our customers, started measuring developer satisfaction, and advocate for a product mindset in our teams. While sounding basic, customer-centricity was not something our previous "Tech Infrastructure" department was known for.
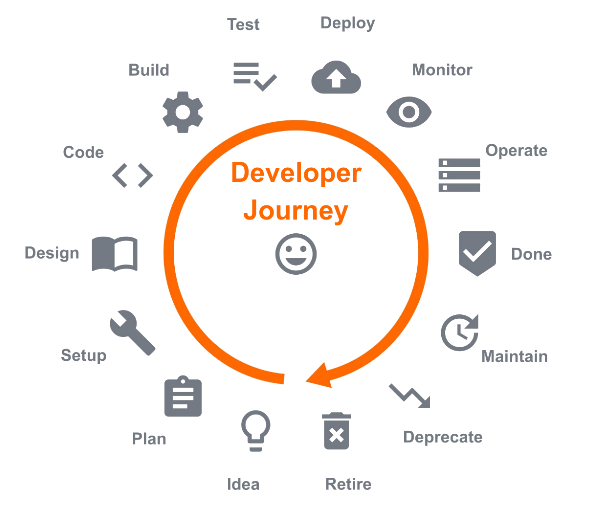
We introduced Kubernetes in 2017 to address the pain points we experienced with AWS/STUPS and created the "Developer Journey" model for our platform products.
2018 was a year where I felt we really had impact for our customers (developers). We introduced the Cloud Native Application Runtime (Kubernetes and CI/CD), our Developer Console got better, and the documentation publishing platform was born. Our build and deployment tooling now provides continuous deployments to Kubernetes by default. The user interface showing CI/CD pipelines looks like this:

Our improvements also show in the increase of developer satisfaction from Q4 2017 to Q4 2018:
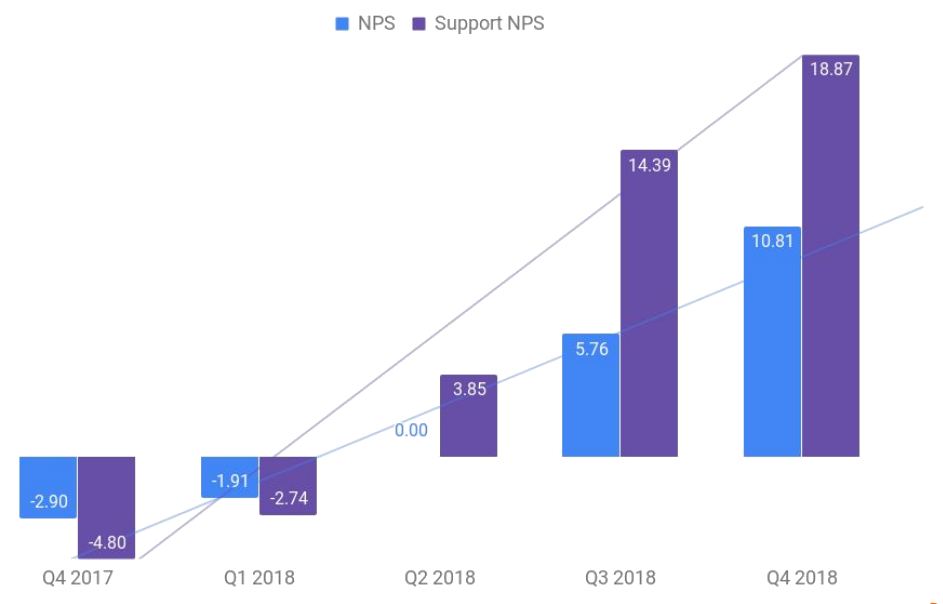
Our goal was and is to build products internal teams love.
From General Management to Individual Contributor
2019 was challenging. I realized that people leadership is neither my strong suit nor my main motivation. Luckily, there was the opportunity to switch to the individual contributor track. Head became Senior Principal. A colleague took over my Head position for Developer Productivity. I'm very grateful for making this change possible.
2019 was a year of public talks. I gave talks at DevOps Gathering 2019, JAX DevOps London, KubeCon Barcelona, DevOpsCon Berlin, ContainerDays Hamburg, CloudNative Prague, OpenInfra Nordics, Enterprise Cloud Native Summit, GOTO Berlin, and AWS re:Invent.
2019 was a year of Kubernetes. I started a collection of Kubernetes Failure Stories (k8s.af) and a few open source projects (e.g. Kubernetes Web View) which are used at Zalando. We officially announced the sunset date for our AWS/STUPS platform and kicked-off a company-wide Kubernetes migration project.

2019 was also the year of our most successful Cyber Week. OpenTracing, load testing, and overall better preparation led to a reliable microservices platform handling 7,200 orders per minute on Black Friday.

2020 just started. There are many interesting initiatives to improve the developer experience, our tech landscape, and achieve productivity at scale. Some initiatives address home-made issues from our "wild times" (2015+). Other initiatives are born out of scale: how to improve collaboration for 260+ engineering teams? How to achieve the best experience for more than 1,300 developers? How to manage a tech landscape with more than 4,000 applications? How to manage and increase efficiency for 140+ Kubernetes clusters? How to accelerate our tech organization?
Learnings
I wrote five bullet items as learnings in my 2013 blog post. How would these look like today?
Be productive — delete code! My first bullet item from 2013 still holds true today. We are still dealing with monoliths from 2010 and functionality is implemented twice in some cases. Deleting unused/deprecated code is like paying back a credit: you now have more room to create/improve functionality for customers.
Nudge with defaults! Defaults are powerful. You want to nudge people towards CI/CD? Provide it out-of-the-box! We don't nudge enough yet: gradual roll-outs, smoke tests, etc are not yet part of a default pipeline.
Think about constraints early! Team autonomy cannot stand above all else in a large organization — it's much easier to relax constraints than to enforce them afterwards. What is your 95% use case? Set constraints for it and allow exceptions for the other 5%. Without constraints you end up not with 95%/5%, but 13%/8%/5%/../1% distributions. For example, baseline rules for tagging cloud resources (AWS and Kubernetes) should be enforced from the get-go.
Get better at scale! If you do a product for multiple years, you should get better at doing it. Not only in providing customer value, but also in terms of cost efficiency. While new innovative products don't need to care about scale yet, cost-per-unit should go down for things at scale. Zalando grew 20-25% per year, infrastructure costs need to scale sublinearly.
Accelerate! Limit work-in-progress, work in small batches, have tight feedback cycles — the book Accelerate says it all. However, I think we have to re-train engineering teams that software development can be fast and safe. Trunk-based development and continuous deployments are old ideas, but did not reach every part of the org.
What's next?
Did I imagine working 10 years for the same company and having 14,000 colleagues? No, I joined a small startup which I had never heard of before. A startup selling (only) shoes online and a city I did not plan to live in.
Did I work at four different companies? It certainly feels like it. Not only did Zalando evolve over time, I also had different roles: Software Engineer, Technical Lead, Delivery Lead, Head of Engineering, and Senior Principal. My current role is quite new and I'm excited to see how a community of Principal Engineers can form in Zalando.
There are boundless opportunities in an organization of our scale. Platform topics start to become really interesting with more than 1,300 developers and more than 4,000 applications: developer experience, collaboration, infrastructure scaling, data management, reliability, observability, cost efficiency, and compliance. Just to name a few. Tackling the full application life cycle including deprecation and retirement is another topic of interest (which was irrelevant in the first years of Zalando).
Life at Zalando will stay more than exciting :-)
PS: If you are intrigued, check out the Zalando jobs page.