Why Kubernetes?
Posted: | More posts about kubernetesThere was a recent blog post by Matthias Endler on why you might not need Kubernetes. I'll try to explain why I believe Kubernetes is worth a close look, even if you just want to run some containers.
DISCLAIMER: No surprise: I'm biased. We run 100+ Kubernetes clusters at Zalando and I'm heavily invested in the Kubernetes topic (as you can see from my github repos). Nobody needs to hear my opinion, so here it is ;-)
Matthias Endler writes:
"Kubernetes is the 800-pound gorilla of container orchestration. It powers some of the biggest deployments worldwide, but it comes with a price tag.
Especially for smaller teams, it can be time-consuming to maintain and has a steep learning curve."
I argue that Kubernetes' cohesive and extensible API matters and that learning it is worthwhile, even if you just want to run a bunch of containers [1].
Running Containers
OK, let's imagine you want to run a bunch of containers, what are your options (sorted alphabetically)?
AWS Elastic Beanstalk (OK, let's just not talk about it)
AWS Fargate ("serverless containers")
docker run(yes, a very viable option!)Kubernetes (managed or self-hosted)
(add your favorite option here)
I only listed options I personally looked into. All of them "work", but differ heavily in what interface they provide: Mesos can provide container orchestration, but does not provide a consistent API (compare Marathon and Chronos) and I haven't met anyone recently who uses it [2]. AWS ECS, Beanstalk and Fargate are options to run containerized workloads, but like all proprietary AWS products, they demand a certain commitment to AWS' way of doing things. This means having a non-extensible AWS API with rate limiting [3], and relying on AWS Lambda as "glue". AWS ECS is used by many organizations and has proven to be a reliable option, but it only provides a limited set of features and a non-extensible API. Blox tried to address some of the shortcomings, but it seems to have stalled (last commit >1 year ago). Nomad seems to be a great project with focus on simplicity and good integration with the HashiCorp landscape, but it comes with a much more narrow, non-extensible HTTP API.
Kubernetes API
Looking at above options, the Kubernetes API is the unique selling point for me. It:
provides enough abstractions to cover most application use cases: rolling deployments, service endpoints, ingress routing, stateful workloads, cron/batch jobs
provides consistency (general structure, OpenAPI schema, version, metadata labels/annotations, spec, status fields)
is extensible via custom annotations, Custom Resource Definitions (CRDs), and API server aggregation
provides a certain compatibility guarantee (versioning)
is widely adopted (all major cloud providers have hosted solutions) and has a huge ecosystem build on top of it
works across environments and implementations: as a naive user of the Kubernetes API I actually don't have to care about how the nodes are implemented (or whether they are "virtual")
I can create Open Source tools like kube-ops-view, kube-downscaler, and kube-janitor, knowing that they will work on any standard Kubernetes API, regardless of managed or self-hosted. There is no incentive for me personally to invest my time in something proprietary like AWS ECS which I don't use at home and which has limited market share. I think this network effect will prevail and we will see more and more high-level tools (apps, operators, ..) for Kubernetes.
Why does it matter that the Kubernetes API is extensible? Having an extensible API matters as you will sooner or later hit a use case not reflected 100% by your infrastructure API, and/or you need to integrate with your existing organization's landscape. Kubernetes allows you to extend its API with custom resources (CRDs), e.g. Zalando uses this to integrate its existing OAuth infrastructure for service-to-service authentication. Custom resources also allow building higher-level abstractions on top of core concepts, e.g. the Kubernetes StackSet Controller adds a new (opinionated) StackSet resource to the API for managing application life cycle and traffic switching. More common use cases for custom resources are the plentiful Kubernetes Operators. These operators define new CRDs for workloads like PostgreSQL, etcd, Prometheus, or Elasticsearch [4].
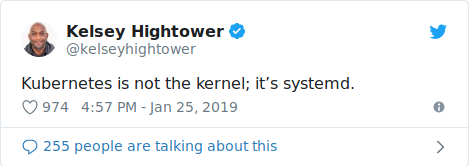
I'm probably not the first to write this, but I often compare the Kubernetes API with the Linux Kernel: the "world" converged towards the Linux Kernel API (when we talk about "containers", >99% of the time it refers to Linux Kernel features like cgroups/namespaces), now we see a similar trend for the Kubernetes API. Or maybe it's not the Kernel, but systemd?
Running Kubernetes
Kubernetes certainly is complex, but setting up Kubernetes does not have to be complex or expensive: creating a cluster on DigitalOcean takes less than 4 minutes and is reasonably cheap ($30/month for 3 small nodes with 2 GiB and 1 CPU each). All major cloud providers have managed Kubernetes offerings, sadly some make it unnecessarily hard to get started. Running Kubernetes on your Raspberry PI also got easier with K3s.
The Kubernetes API is valuable regardless of the implementation: the Virtual Kubelet allows you to run workloads without caring about nodes. Microsoft already provides this feature (AKS Virtual Nodes) in their Azure cloud. You can even experiment with virtual-kubelet and AWS Fargate.
There are now plenty of options to run the Kubernetes API locally for development or testing:
Minikube (kvm or Virtualbox)
kind (Kubernetes in Docker, especially for CI/CD pipelines)
k3s (lightweight Kubernetes, can run on your Linux desktop or Raspi)
While it has never been easier to run Kubernetes locally, the new projects like kind and k3s still have to mature over time.
Matthias Endler wrote in his blog post:
"The takeaway is: don't use Kubernetes just because everybody else does. Carefully evaluate your requirements and check which tool fits the bill."
I can certainly agree with that statement, but from my anecdotal experience, people starting with container orchestration often discount the value of the "standard" Kubernetes API (it's just not part of their requirements list) --- they are surprised when I tell them that the de-facto standard, extensible API is my main argument for Kubernetes. I got to know companies switching from AWS ECS to EKS exactly for this reason: they had to solve problems specifically for ECS where for Kubernetes they could use existing Open Source tooling created for the Kubernetes API. While you should not just jump on Kubernetes "because everybody does it", its long list of users (organizations) is certainly an advantage, especially for learning about production operations. I started collecting Kubernetes Failure Stories for no other reason than to leverage the enormous community and improve infrastructure operations (true for managed and self-hosted). I have yet to see a similarly extensive list for other container orchestration systems --- and believe me: not finding failure stories does not mean there are none ;-)
Summary
You will have to invest in your infrastructure either way, even for managed platforms like ECS you will need to learn specific concepts, abstractions, and pitfalls. I believe that Kubernetes allows you to better utilize the acquired knowledge across cloud providers, environments, and even employers.
I think you should not underestimate Kubernetes' complexity, but you should also not discount the value of the Kubernetes API and its ecosystem.
And don't forget that nobody will care about Kubernetes in five years --- because it becomes ubiquitous ;-)
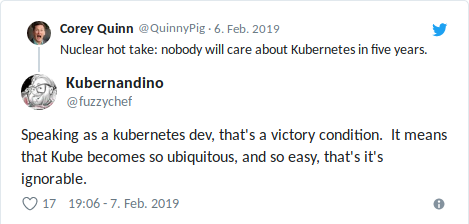
This is the Internet. It's full of opinions. Make your own decision and know the trade-offs.