Liveness Probes are Dangerous
Posted: | More posts about kubernetesKubernetes livenessProbe can be dangerous. I recommend to avoid them unless you have a clear use case and understand the consequences.
This post looks at both Liveness and Readiness Probes and describes some "DOs" and "DON'Ts"
My colleague Sandor recently tweeted about common mistakes he sees, including wrong Readiness/Liveness Probe usage:
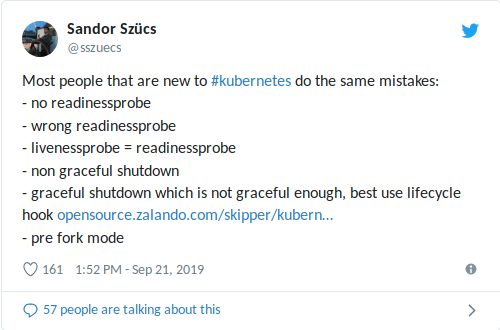
A wrong livenessProbe setting can worsen high-load situations (cascading failure + potential long container/app start) and lead to other negative consequences like bringing down dependencies (see also my recent post about K3s+ACME rate limits). A Liveness Probe in combination with an external DB health check dependency is the worst situation: a single DB hiccup will restart all your containers!
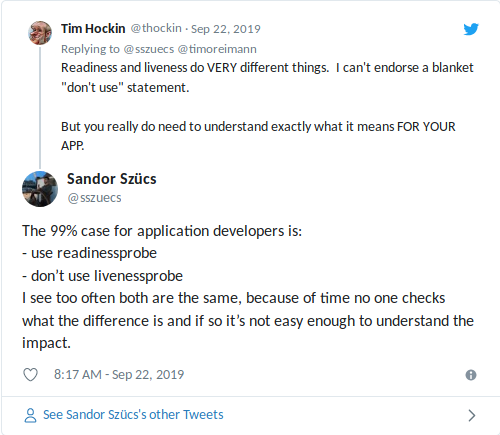
A blanket statement of "don't use Liveness Probes" is not helpful, so let's look at what Readiness and Liveness Probe are for. NOTE: most of the following text was initially put together for Zalando's internal developer documentation.
Readiness and Liveness Probes
Kubernetes provides two essential features called Liveness Probes and Readiness Probes. Essentially, Liveness/Readiness Probes will periodically perform an action (e.g. make an HTTP request, open a TCP connection, or run a command in your container) to confirm that your application is working as intended.
Kubernetes uses Readiness Probes to know when a container is ready to start accepting traffic. A Pod is considered ready when all of its containers are ready. One use of this signal is to control which Pods are used as backends for Kubernetes Services (and esp. Ingress).
Kubernetes uses Liveness Probes to know when to restart a container. For example, Liveness Probes could catch a deadlock, where an application is running, but unable to make progress. Restarting a container in such a state can help to make the application more available despite bugs, but restarting can also lead to cascading failures (see below).
If you attempt to deploy a change to your application that fails the Liveness/Readiness Probe, the rolling deploy will hang as it waits for all of your Pods to become Ready.
Example
Example Readiness Probe checking the /health path via HTTP with
default settings (interval: 10 seconds, timeout: 1 second, success
threshold: 1, failure threshold: 3):
DOs
for microservices providing an HTTP endpoint (REST service etc), always define a Readiness Probe which checks that your application (Pod) is ready to receive traffic
-
make sure that your Readiness Probe covers the readiness of the actual webserver port
when using an "admin" or "management" port (e.g. 9090) for your
readinessProbe, make sure that the endpoint only returns OK if the main HTTP port (e.g. 8080) is ready to accept traffic [1]having a different port for the Readiness Probe also can lead to thread pool congestion problems on the main port which are not reflected in the health check (i.e. main server thread pool is full, but health check still answers OK)
-
make sure that your Readiness Probe includes database initialization/migration
use
httpGetfor Readiness Probes to a well-known health check endpoint (e.g. /health)-
understand the default behavior (interval: 10s, timeout: 1s,
successThreshold: 1,failureThreshold: 3) of probesthe default values mean that a Pod will become not-ready after ~30s (3 failing health checks)
-
do use a different "admin" or "management" port if your tech stack (e.g. Java/Spring) allows this to separate management health and metrics from normal traffic
but check point 2
-
you can use the Readiness Probe for prewarming/cache loading if needed and return 503 status code until the app container is "warm"
check also the new
startupProbeintroduced in 1.16
DON'Ts
-
do not depend on external dependencies (like data stores) for your Readiness/Liveness checks as this might lead to cascading failures
e.g. a stateful REST service with 10 pods which depends on a single Postgres database: when your probe depends on a working DB connection, all 10 pods will be "down" if the database/network has a hiccup --- this usually makes the impact worse than it should
note that the default behavior of Spring Data is checking the DB connection [3]
-
"external" in this context can also mean other Pods of the same application, i.e. your probe should ideally not depend on the state of other Pods in the same cluster to prevent cascading failures
Your mileage may vary for apps with distributed state (e.g. in-memory caching across Pods)
-
do not use a Liveness Probe for your Pods unless you understand the consequences and why you need a Liveness Probe
Liveness Probe can help recover "stuck" containers, but as you are fully owning your application, things like "stuck" processes and deadlocks should not be expected --- a better alternative is to crash on purpose to recover to a known-good state
a failing Liveness Probe will lead to container restarts, thus potentially making the impact of load-related errors worse: container restart will lead to downtime (at least your app's startup time, e.g. 30s+), thus causing more errors and giving other containers more traffic load, leading to more failing containers, and so on
Liveness Probes in combination with an external dependency are the worst situation leading to cascading failures: a single DB hiccup will restart all your containers!
-
if you use Liveness Probe, don’t set the same specification for Liveness and Readiness Probe
you can use a Liveness Probe with the same health check, but a higher
failureThreshold(e.g. mark as not-ready after 3 attempts and fail Liveness Probe after 10 attempts)
-
do not use "exec" probes as there are known problems with them resulting in zombie processes
Summary
use Readiness Probes for your web app to decide when the Pod should receive traffic
use Liveness Probes only when you have a use case for them
incorrect use of Readiness/Liveness Probes can lead to reduced availability and cascading failures
Further Reading
UPDATE 2019-09-29 #1
On init containers for DB migrations: added a footnote.
EJ reminded me about PDBs: one problem of Liveness Probes is the missing coordination across a fleet of Pods: Kubernetes has Pod Disruption Budgets (PDB) to limit the number of concurrent disruptions that an application can experience, but PDBs are not respected by probes. Ideally we could tell K8s "restart one pod if its probe fails, but don't restart all of them to not make it worse".
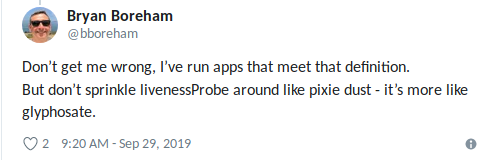
Bryan put it nicely: "Use a liveness probe when you know for sure the best possible thing to do is to kill your app." and don't sprinkle them like pixie dust:
UPDATE 2019-09-29 #2
On "read the docs before using": I created a feature request for the Kubernetes documentation about Liveness Probes: https://github.com/kubernetes/website/issues/16607